最近我用它做了一個小站�。目的很簡單���。我想更新小說并盡快出版。本來想用機車解決的�����,但是沒有模塊流氓�。插入了wordpress 文章采集wordpress 文章采集,但是表格有點麻煩���,遙控器有點慢�。想到的主要思想就是不要重新發(fā)明輪子�,所以在pypi里找了,主要功能就不說了��。詳情請參考官網(wǎng):
目前模塊已經(jīng)更新到 2.2 版本��,但我使用的是 1.5 版本���。懶惰的同學(xué)可以這樣安裝����。
Wget --no-check-
tar zxf ---1.5.tar.gz
cd ---1.5
setup.py
模塊就介紹到這里wordpress做網(wǎng)站,其他功能參考官網(wǎng)介紹����。說說方案思路吧。
1�����、使用記事本記錄已爬取的網(wǎng)址�����。
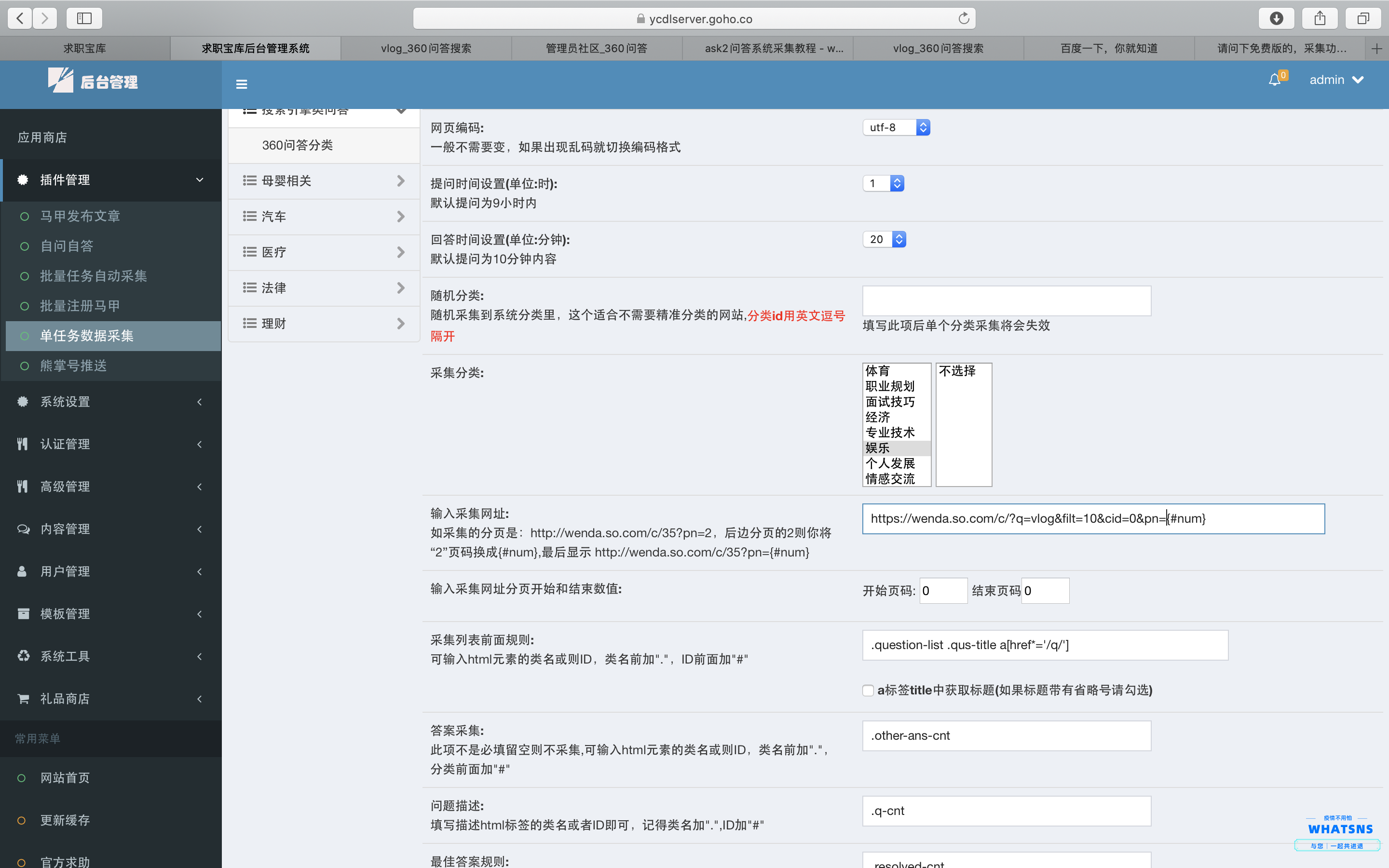
2�、再去爬取這個頁面,得到這個頁面上所有文章的url����。
3、用于檢查此頁面的完整 URL 是否為 TXT 格式����。
4��、如果不存在���,抓取該URL的標(biāo)題和內(nèi)容發(fā)送到,并將URL寫入txt
5�、最后,使用自動任務(wù)�����,每天定時運行����。
代碼如下:(為了防止部分同學(xué)白拿東西����,用圖片代替代碼,紅色部分是URL�、賬號、密碼���、保存URL地址的txt)
@ >
當(dāng)然���,代碼有一個小問題就是沒有定義類別�����。其實定義發(fā)布分類也是可以的����,只是我比較懶wordpress網(wǎng)站建設(shè)����,寫了默認(rèn)文章分類并在后臺設(shè)置目錄。
然后設(shè)置為每小時更新一次����。不會設(shè)置的自我提升。

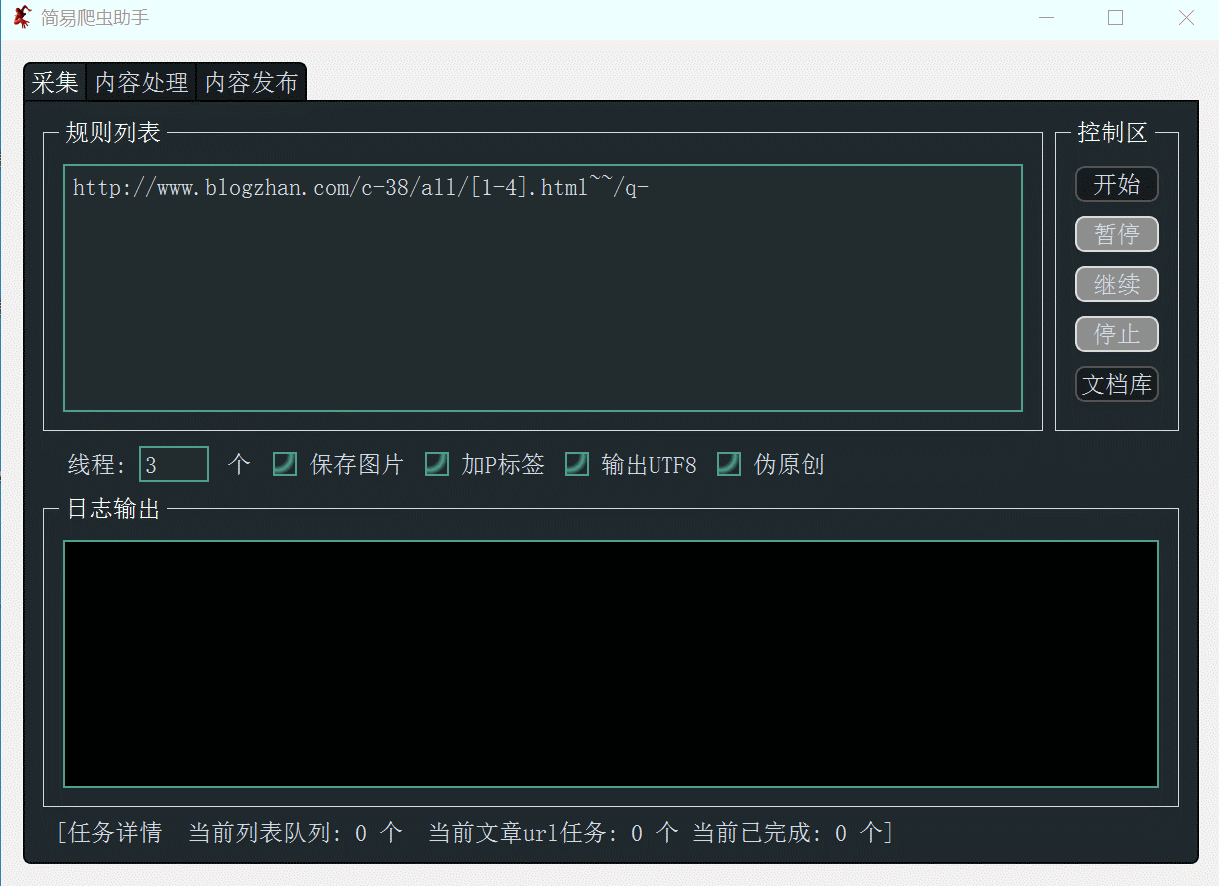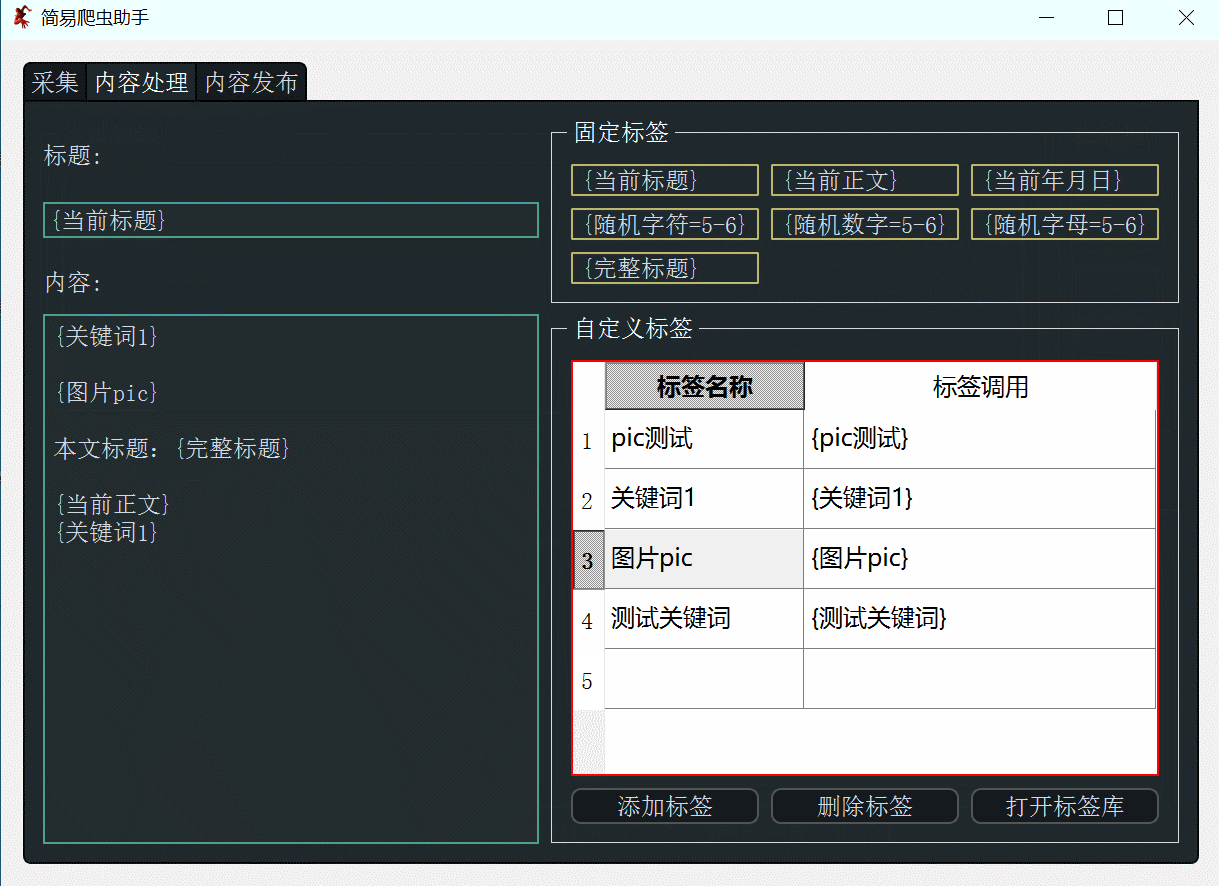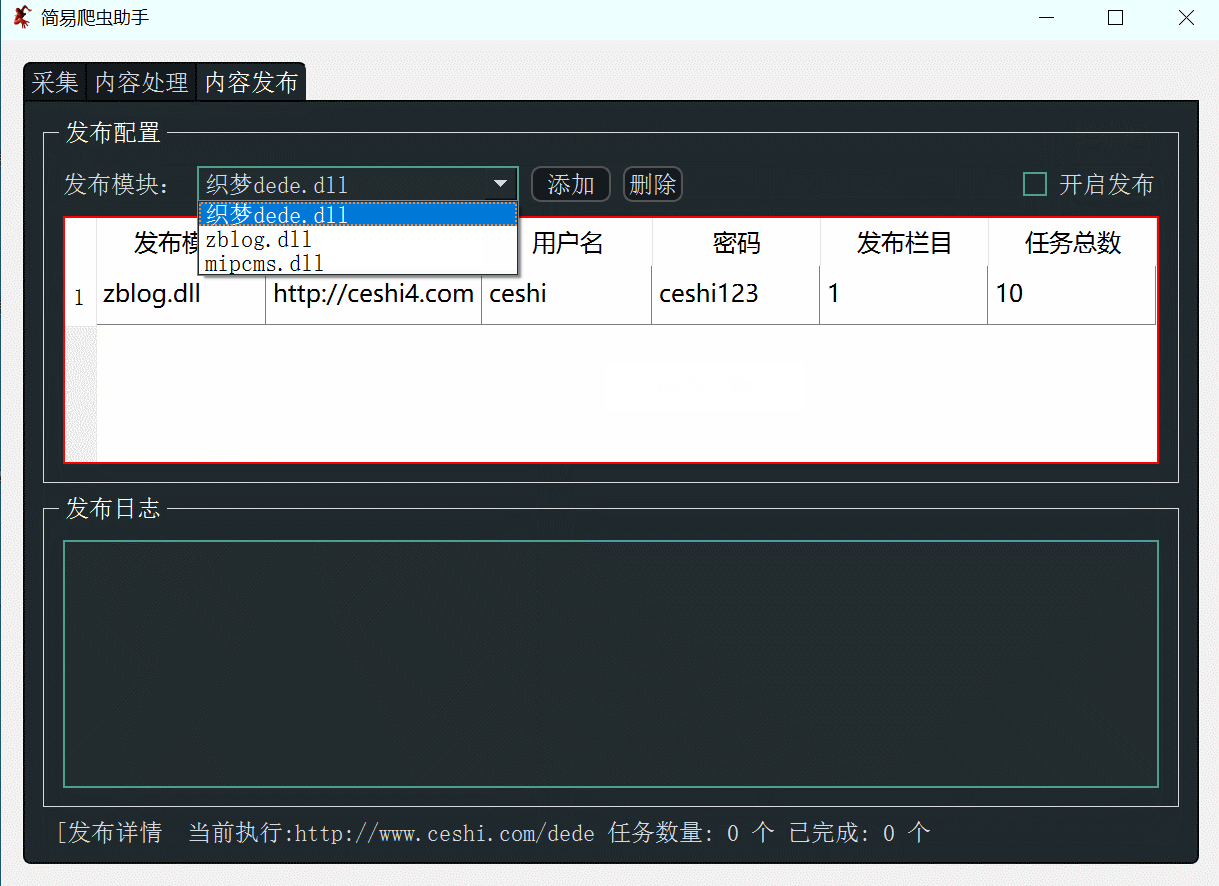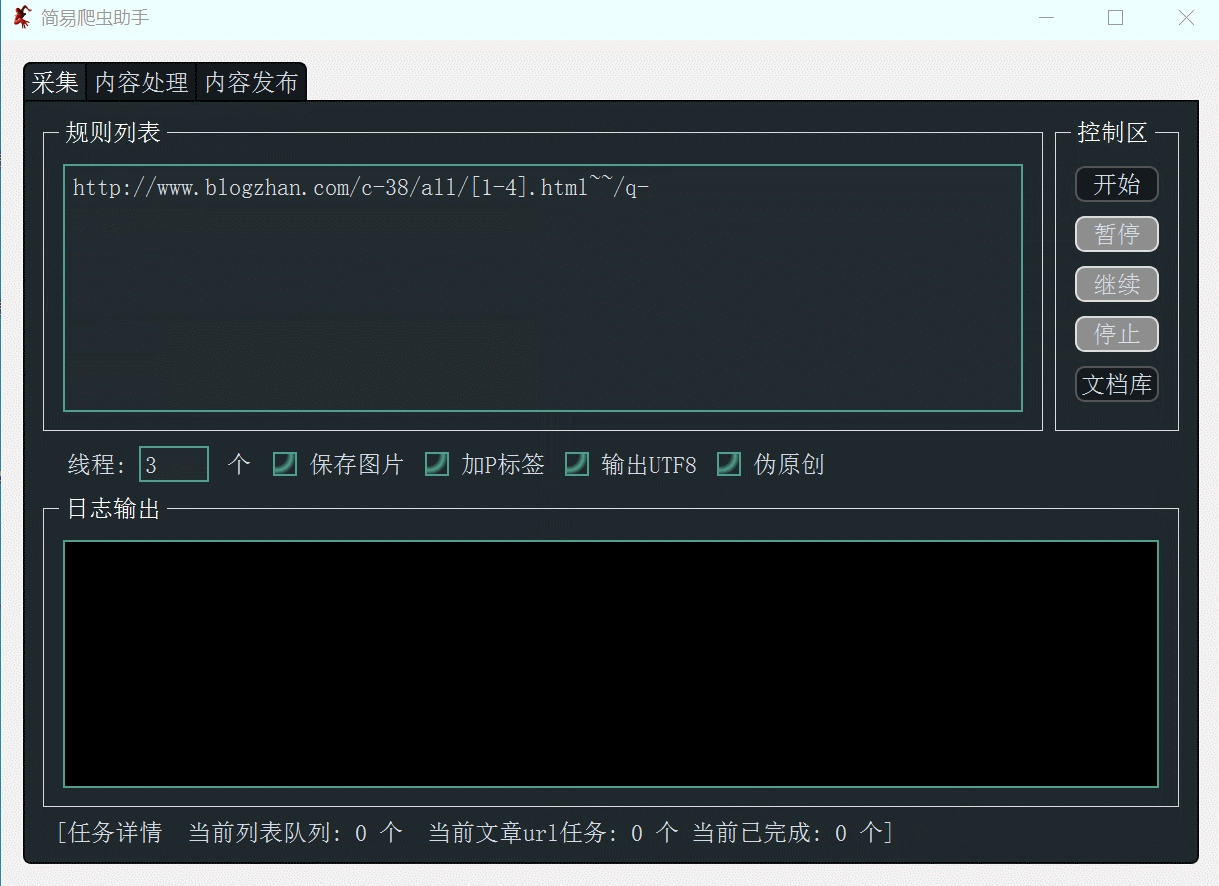
原創(chuàng)內(nèi)容:
蝸牛博客提供的源碼():
f = open('daily_posted.txt','r') #需要先建立posted.txt文件�����。
urls = f.read()
def update_dayly():
#news_url是要采集的網(wǎng)址���。
for news_url in urls:
if news_url not in urls:
mylog.write_log('開始采集{}的數(shù)據(jù)'.format(news_url))
open('daily_posted.txt','a+',encoding='utf-8').write(news_url+'\n')
# scape_url(news_url)
result = get_details(news_url)
if result:
title = result[0]

post_content = result[1]
keyword_list = text2list(category+".txt")
title_keyword = random.sample(keyword_list,1)
if len(title) < 10:
title = "["+title_keyword[0] + "]"+ title
mylog.write_log("文章標(biāo)題:" + title)
mylog.write_log("文章內(nèi)容" + post_content)
mylog.write_log("正在發(fā)布第{}篇文章".format(n))
post_wordpress(title,post_content,category,title_keyword[0])
mylog.write_log("已經(jīng)完成第{}篇文章的發(fā)布..........".format(n))
mylog.write_log("*"*20)
else:
mylog.write_log('當(dāng)前文章之前已經(jīng)發(fā)布過��,略過......')
mylog.write_log('-'*70)
文章來自互聯(lián)網(wǎng)�,侵權(quán)請聯(lián)系刪除,文章闡述觀點來自文章出處���,并不代表本站觀點�。
www.bjcthy.com

